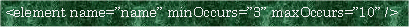技術解説 ‐XML Schema -
2002年5月1日
情報技術開発株式会社 技術統括部
高橋 洋
最も単純な言い方をすると、XMLスキーマ(以後XMLスキーマとカナで記述される場合はXMLスキーマ全般を指し、XML Schemaとアルファベットで記述される場合にはW3Cで承認されているXMLスキーマであるXML Schemaを指すものとします)とはある特定の語彙体系に所属する一連のXMLインスタンスドキュメントの表記構造をXML自身によってメタ定義する為のメタ定義言語であると言えます。従って、XMLスキーマが表現する対象はインスタンスドキュメントの内容自体では勿論なく、いくつかのインスタンスドキュメントが共有して持つドキュメント構造そのものであり、別の言い方をすれば個々のインスタンスドキュメントが意味あるものとして成立するそのコンテクストの語彙体系を明確化する為の1つの表現手段がXMLスキーマであると言うことが出来ます。この意味で言えばXMLスキーマとは単にドキュメントの構造的側面をメタ表現する為のものであるという以上の意味があるとも言うことが出来、後述するXMLの名前空間の考え方と合せて、ある特定のドキュメント構造を共有する一連のインスタンスドキュメント群が有効であるものとして認識されるシステム範囲及びその構造を決定する為の一種の媒介的機能も有するとも考えることが出来ます。
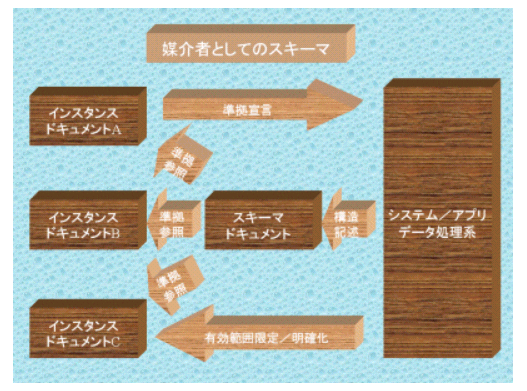
たとえばあるXMLインスタンスドキュメントの内容と別のXMLインスタンスドキュメントの内容が仮に構造的にも正確に一致していたものとしても、この事実からのみではこの2つのドキュメントが有効であるシステムコンテクストが全く同じであると見なすことは出来ません。またあるインスタンスドキュメントの内容は必ずしもただ1つのシステムコンテクストのみに関連付けられると言い切ることも出来ません。また更に注意する必要があるのは、システムコンテクストとは必ずしも特定のシステムコンテクストのただ1つの実装に対応することを意味しているわけではなく、該当するシステムコンテクストを実装する複数のシステム実装を意味しても一向に構わないということです。たとえば、後述するXML Schema固有の名前空間によって識別される語彙体系は、ただ1つのアプリケーション又はシステムの実装(たえばある特定のバリデータ)によって有効と見なされ参照されるのではなく、XML Schemaをサポートする全てのアプリケーション又はシステム(この中にはバリデータあり後に紹介するデータバインディングアプリケーションありと多岐の機能に渡る場合も当然あります)によって参照されることになります。この要請が実現される為には、たとえばオブジェクト指向におけるインターフェースの考え方が特定の処理の実装と処理の実装には影響されない抽象を明確に区別する方法を提供したのと同様な意味において、何らかのメタ記述によってサポートされる媒介的なすなわち特定のシステム実装様式に縛られることのないシステム空間記述方式が必要不可欠になるということをも意味しています。XMLの名前空間の考え方は、ある特定のシステムコンテクストが有効である範囲を特定のシステムの実装に依存することなく明確化し、それに対する一意参照を可能にする命名手段であると言い換えることが出来ますが、XMLスキーマはこの名前空間が差し示す1つのシステムコンテクストが理解する語彙構造を特定のシステムの実装に依存することなく明確に記述する為の用具であると言うことが出来ます(但し5章で簡単に触れますがXML Schemaを始めとするXMLスキーマの多くはインスタンスドキュメントの文法構造の規定に主眼がありますが、Schematronのように必ずしも文法規定に主眼があるわけではないXMLスキーマも存在し、このようなXMLスキーマにはここで述べた議論は若干当て嵌まらない面があります)。
かくしてXMLスキーマは、複数のXMLインスタンスドキュメントが共有する語彙構造の一意的な定義を可能にしますが、XMLスキーマ自体XMLで記述されることがほとんどであり、パーサ等のアプリケーションを通じてコンピュータシステムにフィードすることが出来、システム内でインスタンスドキュメントの整合性チェック(バリデーション)等の種々の目的に使用することが出来ます。またもう1つ重要な点は、単にコンピュータに対する入力としてだけではなく、人間の目から見た場合にも特定のシステム或いはアプリケーションドメインが有効であると見なす語彙構造が一意的に明確化される為、特定のシステム情報に関する人と人との間でのコミュニケーションシーンにおいても大きな意義を持ち得るということが挙げられます。たとえばSOAP、UDDI、WSDL等のXMLを利用した規格には、XML Schemaによる構造規定が付加されていますが、これはそれぞれの規格(システム)の利用者に対してそれぞれの規格が有効であると見なす語彙構造を可能な限り曖昧さのない様式で表現することがその目的であると言ってもよいでしょう。
さてこのXMLスキーマには、当技術解説がターゲットとするW3CによりRecommendationとして承認されているXML Schemaの他にもいろいろな種類があり、たとえば、Microsoft社他によるXDR、AT&T研究所等によるDSD、Rick Jelliffe氏によるSchematron、村田真氏及びJames Clark氏によるRelax NG等があります。また従来から利用されてきたDTDもXML自体では記述されないとはいえどもXMLスキーマの1つであると位置付けることが出来ます。これらのXMLスキーマにはそれぞれ一長一短があり、どれが絶対的に優れているというような比較をすることは出来ません。尚、この技術解説書では、紙幅の都合等もありますのでW3Cで承認されているXML Schemaをメインターゲットとします。
XML Schemaは、2001年5月にRecommendationとしてW3Cにより承認されました。XML Schemaは、大きく分けて「XML Schema Part 1:Structures」と「XML Schema Part 2:Datatypes」の2つのパートに分かれており、前者ではXML Schemaの構造面に関する定義が記述されており、後者では組込みデータ型の定義及びユーザ定義データ型の派生方法等が記述されています。また、初心者用に「XML Schema Part0: Primer」(以後Primerと記します)というパートがこれとは別に存在しており、具体的な例を用いてXML Schemaによる記述の仕方が平易に解説されています。このPrimerを読めば簡単なXML Schemaドキュメントを記述することが出来るようになります。またXML Schemaでの記述の仕方に関するtips等はインターネット上にも既にかなりあり、フォーラム等でも様々な議論が盛んに行われています。
<各XML Schema仕様URL>
さてここでXML Schemaが提案された経緯をDTDと関連させて述べてみます。ご存知のようにXMLドキュメントの構造記述の手段としてはもともとDTDがあり、DTDを利用してのインスタンスドキュメントの文法チェックは既に広く流布していました。しかしながら、DTDではチェック出来ない要件がかなり多くあり、また概要で述べた特定の語彙体系を一意定義する為の手段いう観点において、DTDにはあまり向いていない側面がありました。前者に関して言えば、データ型が殊に要素(element)に関しては無きに等しいことや、要素の出現回数の記述方法が貧弱であるなどのかなりベーシックなレベルの問題が多々ありました。後者に関して言えば、構造記述表現が貧弱であるが故に曖昧な面が残ってしまうという事実(一定の範囲の担当者のみが対象となるローカル使用の場合は、その中でコンセンサスが取れていさえすれば実践的に解決出来る問題ではありますが、それを越えたグローバルな範囲での使用においては曖昧さは1つの問題になり得るでしょう)はもとより、DTDには名前空間のサポートが現状ではないこと及び1インスタンスドキュメント1DTDという制限がある故にどうしてもグローバルな語彙定義を行うには不適切な部分がありました。或る意味においてある一定の範囲内に限られたローカルな環境内を越えたグローバルに通用する語彙体系をDTDを用いて定義することはあまり実際的ではなかったと言えるでしょう。この故結果的に、DTDによる記述はそれが表現する語彙体系を理解するある1つの特定のシステムの実装に強く結びついた語彙定義になってしまいがちであったとも言わざるを得ないでしょう。またDTDにはオブジェクト指向的な継承、派生の概念が全く取り入れられていない為、語彙体系すなわちDTD自体の再利用(特定のDTDに制限を加えたり拡張したりして新たな類似のDTDを生成すること)は不可能であったという問題点もありました。このようなDTDの持つ短所を補完することを1つの目的としてXML Schemaが提唱されたわけですが、当初はバリデータ等のサポートするアプリケーションが限られていたこともありDTDからXML Schemaに切り替えるには実際的な問題がありました。しかしながら、前述したように2001年5月にW3CのRecommendationとして承認されてからは、XML Schemaをサポートするバリデータ等のアプリケーション、或いは何らかの形でXML Schemaを利用するアプリケーションサーバ等の数も増えてきており、今後XMLによるデータ交換等が普及していくにつれXML Schemaの地位はより重要性を増していくのではないかと考えられます。
XML Schemaの機能に関して概略を会得する早道は、「第2章 XML Schemaについて」で紹介した Primerを何はともあれ参照することです。この章では主にこのPrimerに記述されている内容を更に簡略化して紹介します。また、XML Schemaに関する他のインターネットサイトに記述されているTips等にも若干言及します。但し、この技術解説の目的はXML Schemaの機能を網羅的に解説することではありませんので、主な機能や考え方の概説のみに対象を絞ります。尚、この章で紹介する実例の多くはPrimerに記載されているものをなるべく使用するようにします。又、以後XMLインスタンスドキュメント(*.xmlファイル)はインスタンスドキュメント、XML Schemaドキュメント(*.xsdファイル)はスキーマドキュメントと呼ぶことにします。
DTDとは異なり、ある特定のインスタンスドキュメントが参照するスキーマドキュメントは複数あっても構いません。名前空間の扱いに関しては「名前空間」の項で詳述しますが、それぞれのスキーマドキュメントは異なる対象名前空間に属している場合もあり、この場合異なる名前空間に属する要素/属性はコロンセパレータによって付加される接頭辞である名前空間識別子によってインスタンスドキュメント内でも区別される必要があります。尚、あるインスタンスドキュメントが対応するスキーマドキュメントの語彙定義に正確に準拠している場合、このインスタンスドキュメントは対応するスキーマドキュメントに対しvalidであると言います。
XML Schemaにおいては、要素をelementタグによって記述することが出来ると同時にcomplexTypeタグ或いはsimpleTypeタグによって型定義することも出来ます。型によってグローバル記述(後述)される場合には、type属性指定により他の要素定義からその型に対して参照することが可能であり、同一型定義を異なる要素定義から参照することが可能です。また<element>タグによって定義されたグローバル要素定義(後述)はref属性によって他の要素定義から参照することが出来ます。また<element>タグによって記述される要素定義のname属性に一致する要素が対応するインスタンスドキュメント中に出現した時、その要素の構造が正確に要素定義の構造に合致しないと、そのインスタンスドキュメントはそのスキーマドキュメントに対してvalidであるとは見なされません。自身の内に入れ子的に子孫要素を含むような複合要素を記述する為には、既にグローバル定義されている型に参照するか自身の内に型定義を含むか(ローカルな匿名定義)のいずれかにより必ず型定義が必要になります。尚、要素定義或いは型定義が必要であるか否かについては、ケースバイケースであると言えますが、少なくともインスタンスドキュメント内に要素として出現する可能性のないもの、すなわちスキーマドキュメント内での再利用のみが目的であるものは型定義のみによって定義されるべきでしょう。

|
|
<elementタグによる要素定義例>
|
上記例では値がXML Schema組込みデータ型「string」であるような要素「comment」を定義しています。この要素を別の要素定義から以下のようにして参照することが出来ます。

|
|
<要素定義への参照例>
|

|
|
<型定義例>
|
上記例では複合型(後述)「PurchaseOrderType」を定義しています。この型を別の要素定義から以下のようにして参照することが出来ます。
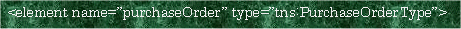
|
|
<型定義への参照例>
|
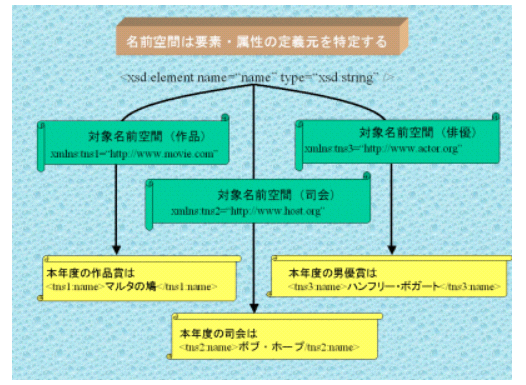
上記例でcomment及びPurchaseOrderTypeの前に付加されているtnsという接頭辞は対象名前空間(すなわち現在のスキーマドキュメントが所属する名前空間)を表していますがこれについては「3-4 名前空間」の項で詳述します。
<element>、<complexType>、<simpleType>のいずれかにより定義される要素、型(今後総称してコンポーネントと呼びます)が、スキーマドキュメントのルート要素である<schema>要素の直下に定義された場合、これらのコンポーネントはグローバルであると呼ばれます。これに対して他のコンポーネントの中に包含されるコンポーネントはローカルであると呼ばれます。グローバルとして定義されたコンポーネントは、ref、type属性を用いて他の要素定義より参照することが出来ますが、ローカルとして定義されたコンポーネントはそれらを包含するコンポーネント内のみにローカライズされます。一部のパワーユーザの間では極限様態として専らローカルコンポーネントによってスキーマを構成する流儀を「Russian Doll(ロシア人形)」パターン、専らグローバルコンポーネントによってスキーマを構成する流儀を「Salami Slice(サラミスライス)」パターンと呼んでいるようですが、実際には両者の混合になることが多いでしょう。どちらの流儀にもそれぞれ一長一短がありますが、コンポーネントの再利用を考慮するならばそれらはグローバルとして定義される必要があります。以下の例で言えば、コンポーネントA及びコンポーネントBはグローバル定義されていますので互いに他のコンポーネントを内部から参照することが出来ます。しかしながら、コンポーネントBの内部に定義されているコンポーネントはローカルなので、これをコンポーネントAの内部から参照することは出来ません。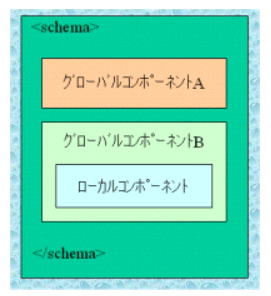
XML Schemaは名前空間をサポートします。各名前空間は、URI表記により一意指定されますが、必ずしも対応するスキーマドキュメントが対応する物理ロケーションに存在しなければならないということを意味するわけではありません(尚、物理ロケーションを示す属性としてschemaLocationがありますが、この属性は他のスキーマドキュメントを後述するincludeまたはimportによって参照する場合及びインスタンスドキュメント内でダイナミックにスキーマドキュメントを指定参照する場合に使用され、これらのschemaLocation指定が必ずしも参照されるスキーマドキュメントで定義されている対象名前空間URIと一致している必要はありません)。
スキーマドキュメント中では、基本的には最低でも2つの名前空間が利用されます。1つはXML Schema固有の名前空間があり具体的なURIはhttp://www.w3.org/2001/XMLSchema固定です。またもう1つは定義対象となっているスキーマドキュメントが所属する名前空間でありtargetNamespace属性により指定されます。また後述するimport機能を利用して他の名前空間に所属する語彙体系を参照することが出来ますので、実際には3種以上の名前空間が利用されることがしばしばあります。この為異なる名前空間の間でのネーミングコンフリクトを避ける為に各要素/属性及びref、type属性内で参照指定される要素/型の名前の先頭にそれが所属する名前空間を特定する接頭辞を付加する必要があり、これを名前空間修飾と呼びます。しかしながら全てのタグに名前空間を特定する接頭辞を付加するとドキュメントが非常に見にくくなることが考慮されており、1つだけデフォルト名前空間を定義することが出来ます。スキーマドキュメント内に関して言えば、最も出現回数が多くなるであろうXML Schema固有の名前空間をデフォルト名前空間とすることが多いようですが、対象名前空間をデフォルト名前空間に指定しても構いませんし或いはそれ以外の名前空間をデフォルトに指定しても構いません。また、デフォルト名前空間を全く指定しなくても構いませんが、この場合は全ての必要箇所に名前空間を特定する接頭辞を付加する必要があります。以下にXML Schema固有の名前空間をデフォルト名前空間とするスキーマドキュメント例を挙げます。

|
|
<デフォルト名前空間=XML Schema固有の名前空間とする例>
|
この例において「xmlns=”http://www.w3.org/2001/XMLSchema”」の部分がデフォルト名前空間の定義になります。XML Schema固有の名前空間がデフォルトである為、XML schema名前空間に所属する<schema>、<element>、<complexType>等の要素には所属名前空間を特定する接頭辞は付加されていません。これに対し上記例では対象名前空間はデフォルト指定されていませんので、たとえ同一ドキュメント内に該当タイプが存在していても「type=”tns:PurchaseOrderType”」のように要素/型名の先頭に所属名前空間を特定する接頭辞が付加されています。尚、以後のサンプル例ではルート要素<schema>は全て省略しますが、上記例のようなルート要素<schema>が定義されているものとします。
インスタンスドキュメント中でも名前空間は、特定の要素/属性が所属する定義元の語彙体系を一意的に特定する為に使用されます。
しかしながらインスタンスドキュメント内での名前空間の扱いは、スキーマドキュメント内と若干異なる点があります。まず最初にインスタンスドキュメントは自分が語彙を定義するわけではありませんので、targetNamespaceの指定はありません。またインスタンスドキュメント内で、XML Schema固有の名前空間に所属する要素を参照することはありませんが、属性に関しては若干の例外があります。たとえば、後述する「3−9 抽象要素、抽象型の定義」の例にもあるようにインスタンスドキュメント中からスキーマドキュメント内に定義されている型に参照する為にtype属性を用いる場合があります。このtype属性はURI= http://www.w3.org/2001/XMLSchema-instanceにより参照される名前空間により規定されている語彙であり、従ってこの名前空間にインスタンスドキュメントから参照する可能性が存在します。他にはnil属性(要素が値を持たない場合xsi:nil=”true”のようにインスタンスドキュメント中に記述することが出来ます)などがあります。この名前空間を指定するために一般には接頭辞xsiを使用するのが慣用であるようですが実際にはxsiでなくとも構いません。最後に、インスタンスドキュメント中においては、ローカルの要素及び属性に関して名前空間修飾が必要である場合と必要でない場合があります。この指定は対応するスキーマドキュメント内で、elementFormDefault(要素)及びattributeFormDefault(属性)を記述することにより変更することが可能です。これらの属性がunqualified(デフォルト)に指定されている場合には、ローカル要素/属性に対して名前空間修飾を行う必要がありませんが、qualifiedに指定されている場合にはこれを行う必要があります。しかしながら後者の場合でも対応する名前空間がデフォルト名前空間として指定されている場合には、勿論名前空間修飾を行う必要はありません。以下に例を示します。

|
|
<ローカル要素/属性の修飾を要求しないスキーマドキュメント例>
|
上記スキーマドキュメントには、elementFormDefaultもattributeFormDefaultも指定されていませんので要素/属性双方に関してデフォルトのunqualifiedであると見なされインスタンスドキュメント中でローカルの要素/属性に関して名前空間修飾をする必要がありません。従って対応するインスタンスドキュメントは以下のようになります。

|
|
<ローカル要素/属性の修飾のないインスタンスドキュメント例>
|
グローバルな要素<purchaseOrder>のみに名前空間修飾子が付加されています。これに対し、スキーマドキュメントの<schema>要素にたとえばelementFormDefault=”qualified”を追加すると対応するインスタンスドキュメントは以下のようになります。

|
|
<ローカル要素/属性の修飾のあるインスタンスドキュメント例>
|
全ての要素に名前空間修飾子が付加されていることに注意して下さい。しかしながら、対応名前空間をデフォルト名前空間にすると以下の例のように名前空間修飾が不要になります。

|
|
<該当名前空間をデフォルト名前空間とした場合>
|
上記例では、対象名前空間がスキーマドキュメントに指定されることを前提としていましたが、スキーマドキュメントに対象名前空間を指定しないことも可能です。この場合対応するスキーマドキュメント中の要素定義/型定義は全て名前空間修飾なしで参照されます。但し、この場合XML Schema固有の名前空間をデフォルト名前空間に指定するとスキーマドキュメントで定義されている要素/型との区別が不可能になる可能性が存在しますので、XML Schema固有の名前空間に対して名前空間修飾が必要となります。尚この対象名前空間をスキーマドキュメントに意図的に指定しないケースに関しては次節「3−5 インクルード(include)とインポート(import)」のカメレオンデザインに関する説明も参照して下さい。
あるスキーマドキュメントから別のスキーマドキュメントのコンテンツを参照することが出来ます。いわばC言語等でのincludeディレクティブによるメカニズムに類似する機能ですが、スキーマドキュメントにおいて大きな問題となるのが名前空間の扱いです。インクルードを用いて他のスキーマドキュメントを参照する場合には、参照元と参照先双方の対象名前空間が同一であるか、又は参照先の対象名前空間が未指定でなければなりません。後者の場合参照先の対象名前空間は参照元の対象名前空間と同一であると見なされます。参考までに付加しておきますと、一部のパワーユーザの間ではこの後者のケースが利用される場合、それをカメレオンデザイン(すなわち参照先ドキュメントの名前空間が参照元ドキュメントの名前空間によって逐一変化するのでカメレオンと呼ばれます)と呼んでいるようです。これに対し、参照元スキーマドキュメントの対象名前空間とは異なる対象名前空間を持つスキーマドキュメントを参照するにはインポートが用いられねばなりません。尚、インクルード又はインポートするスキーマドキュメントは、schemaLocation属性でURI指定しますが、当然のことながらここで指定されるURIに対応する物理ロケーションには、対応するスキーマドキュメントファイルが実在していなければなりません。
XML Schemaでは、型としてそれ自体の内に更に要素/属性/型定義を含むことが出来る複合型(complexTypeタグで表現される)とそれらを含むことが出来ない単純型(simpleTypeタグで表現される)が明確に区別されます。単純型についてはXML Schemaに組込み型としていくつか既に型が用意されていますが(現状では44種類)、これらの組込み型をベースとしてユーザは独自に新しい単純型を派生させることも出来ます。XML Schemaでは15種類の制限記述子(constraining facets)が用意されており、ベースとなる型に制限記述子による制限を加えて新たな型を派生させることが出来ます。尚、制限記述子の種類及びどの組込み型にどの制限記述子が適用可能かはXML Schema仕様を参照して下さい(Primerの付録にある表が便利です)。以下の例は制限記述子minInclusive、maxInclusiveを用いて組込み単純型であるintegerから新たなユーザ定義単純型myInteger(10000以上99999以下整数値)を派生させる例です。

|
|
<ユーザ定義単純型例1>
|
また次の例は、制限記述子enumerationを用いて組込み型stringから新たなユーザ定義単純型USState(合衆国短縮州名リスト)を派生させる例です。

|
|
<ユーザ定義単純型例2>
|
単純型に対して、その自身の内に要素/属性/型定義を含むことが出来る型を複合型と呼びます。従って典型的には、複合型定義は、該当タイプに所属する要素を定義するelementタグ、所属属性を定義するattributeタグ及び更に下位階層を包含する場合には下位の複合型を定義するcomplexTypeタグから構成されます。以下に複合型の定義例を挙げます。

|
|
<複合型の定義>
|
上記例では、5つの要素と1つの属性から構成される複合型Addressを定義しています。尚、要素<sequence>は下位要素が記述の順番にインスタンスドキュメント中に出現しなければならないことを意味し、他にも<all>(出現順序不定)、<choice>(複数要素からの単一要素選択)があります。Validなインスタンスの例は以下の通りです。

|
|
<Validなインスタンス例>
|
オブジェクト指向の考え方には継承(inheritance)を利用したクラスの派生という考え方がありますが、XML Schemaでもそれに類似した機能が用意されており、これにより既存型の再利用を促進することが出来ます。XML Schemaが用意する派生方法には拡張(extention)と制限(restrinction)があり、単純型については制限が、複合型については制限、拡張双方が適用可能です。拡張は、ベースとなる型の持つ要素や属性に新たに要素や属性を加えることによって新たな型を生成します。制限は、単純型の場合には前項「3−6 単純型と複合型」で記述したようにベースとなる単純型に制限記述子を適用することにより、より値の包含範囲の狭い新たな単純型を定義することが出来ます。複合型の場合にはベースとなる型の要素/属性の限定或いは特定要素の出現回数等の減少方向修正(これはベースとなる型を処理するアプリケーションが制限により派生された型を処理する時予期不可能であるような値が出現するような方向に制限を行うことは出来ないということを意味します)により限定することにより、より制限された複合型を定義することが出来ます。複合型の制限を行う場合、制限の対象にならない要素/属性も全て派生される型定義に再記述されねばなりません。尚、イメージ的には拡張による派生がオブジェクト指向の継承の概念に近いということが出来ます。以下に複合型の拡張による派生の例を挙げます。

|
|
<複合型の拡張による派生例>
|
上記例では、拡張派生複合型であるJPAddressは要素として<name>, <street>, <city>, <prefecture>, <zip>から構成されることになります。従ってこれに対応するvalidなインスタンスドキュメントは以下のようになります。

|
|
<Validなインスタンスドキュメント例>
|
DTDには要素の出現回数を指定する方法として無修飾(必ず1回)、?修飾(0又は1回)、+修飾(1からn回)、*修飾(0からn回)がありましたが、これのみではたとえば「要素A中に要素Bが3回以上10回以下出現する」を表現するには、
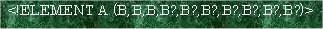
|
|
<DTDによる要素出現回数指定例>
|
というように記述するしかありませんでした。ましてや「要素A中に要素Bが100回以上200回以下出現する」などという表現は実際的には記述不可能であったと言わざるを得ないでしょう。これに対してXML Schemaでは要素の出現回数を指定する属性としてminOccursとmaxOccursが用意されており正確に要素出現回数を指定することが可能です。尚、minOccurs、maxOccursそれぞれのデフォルト値は1です。またmaxOccurs=”unbounded”と指定されるとMAX出現回数は無制限となります。
要素出現回数指定例
オブジェクト指向には抽象親クラス(あるクラスがシグニチャのみで実装を全く含まない抽象メソッドを1つでも有する場合このクラスは抽象クラスと呼ばれ、抽象メソッドの処理の実装は抽象クラスを継承した子クラスが行うことになります)という考え方がありますが、XML Schemaでもこれとメカニズム的には類似した機能が用意されています。すなわち要素又は型をabstractとして定義することが可能です。まず抽象要素の定義ですが、これは要素をabstractとして定義する方法であり、インスタンスドキュメント中ではその要素を代替グループ(その要素をsubstitutionGroup属性により参照する要素で、インスタンスドキュメント中で参照先要素が出現可能な箇所には参照元要素も出現可能です)として参照する要素が、abstractとして指定されている要素の代わりに出現することが可能です(abstractとして定義されている要素は、そのままではインスタンスドキュメント中に出現することが出来ません)。これにより、インスタンスドキュメントの特定箇所に代替グループとしてタイプを共有する複数種の要素がポリモルフィックに出現可能になります。以下に例を挙げます。

|
|
<抽象要素定義例(前半部)>
|
<VehicleCatalogue>要素には、<Vehicle>要素が1回以上出現します。しかしながら<Vehicle>要素はabstract=”true”として定義されていますので、インスタンスドキュメント中にそのまま出現することは出来ません。

|
|
<抽象要素定義例(後半部)>
|
<Car>要素及び<AirPlane>要素は、<Vehicle>要素を代替グループとして参照しますので、<Vehicle>要素が出現可能な位置には、<Car>要素及び<AirPlane>要素も出現可能です。従って、abstract宣言されている<Vehicle>要素自体はインスタンスドキュメント中には出現出来ませんが、その代わりとしてabstract宣言されていない<Car>要素、<AirPlane>要素は出現可能です。尚、<Car>要素、<AirPlane>要素が<Vehicle>要素の代替グループに所属する為には、<Car>要素、<AirPlane>要素の参照する型すなわちCarType、AirPlaneTypeは、<Vehicle>要素の参照する型すなわちVehicleTypeの派生型でなければなりません。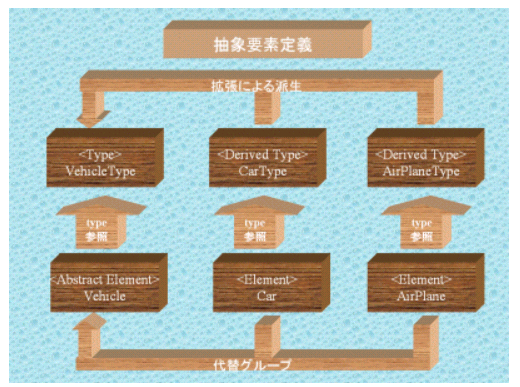
上記スキーマドキュメントにvalidであるインスタンスドキュメントはたとえば以下のようになります。

|
|
<Validなインスタンスドキュメント例>
|
この方法が再利用というコンテクストにおいて有効であるのは以下のようなケースにおいて明らかになります。すなわち、自分が担当する部署において新たに<VehicleCatalogue>要素の子要素として<Ship>要素を独自に追加したいけれども既存の定義を変更する権限が自分にはないというようなケースです。この場合以下のような定義を持つスキーマドキュメントを担当部署で作成し、インスタンスドキュメント中のschemaLocation定義でこの新たに作成されたスキーマドキュメントを参照すればよいことになります。

|
|
<新たな要素を追加する場合>
|
しかしながらインスタンスドキュメントを処理するアプリケーションの観点から見た場合にはこの方法は必ずしも再利用性を保証するとは言えない側面が存在します。何故ならばアプリケーションにとっては予期せぬ要素が追加される可能性が存在するからです。たとえば最も単純な例を挙げますと、以下のように記述されたXSLTは新しい要素が追加されると有効に機能しなくなるでしょう(新規追加要素が全く処理されない為)。

|
|
<新規追加要素は処理されない>
|
次に抽象型の定義についてですが、これは要素ではなく型をabstractとして定義する方法です。abstract定義されている型をtypeによって参照する要素定義に対応するインスタンスドキュメント中の要素については、このabstract型を派生して定義されるabstractではない型をtype属性を用いて指定しなければなりません。以下は上記抽象要素定義例を抽象型定義による例に置き換えたものです。

|
|
<抽象型定義例>
|
抽象要素定義例と違い、要素<Vehicle>は抽象指定されておらず、その代わりに要素<Vehicle>が参照する型VehicleTypeがabstract=”true”により抽象指定されていることに注意して下さい。CarTypeとAirPlaneTypeの定義は、抽象要素定義例と同様ですが対応する要素定義はありません。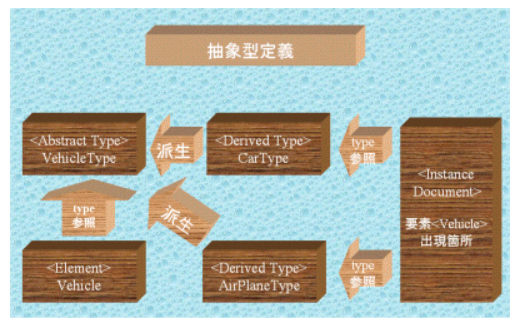
対応するValidなインスタンスドキュメントは以下のようになります。

|
|
<Validなインスタンスドキュメント例>
|
各<Vehicle>要素にはtype属性により対応する型(抽象型より派生する型)が指定されていることに注意して下さい。この方法においても新たにVehicleTypeを派生する型を定義すれば新たな型の追加が可能になります。またこの追加により、このスキーマを参照するインスタンスドキュメントを処理するアプリケーションを修正しなければならなくなる可能性は抽象要素定義例の場合よりも少なくなるでしょう。何故ならばこのケースでは、アプリケーションにとって予期せぬ名前を持つ要素が追加されるわけではないので、要素を参照処理するアプリケーションに対する変更は、少なくとも既存の共通要素に関して必要となる処理については発生しないからです。
XMLの構造は本来ツリー構造なので従来よりあるRDBの構造と必ずしも親和性があるとは言えない側面があります。しかしながら業務処理を考慮に入れると、たとえ入出力シーンにおいてはツリー構造的XMLインスタンスドキュメントを処理するとはいえどもRDB的構造を考慮に入れる必要性が必ずや発生するであろうことが予想されます。その為、XML Schema定義においてもRDB的な関係構造を記述する為の一意性指定とキー参照定義の仕組みが用意されています。一意性指定を用いると、特定の属性/要素或いはそれらの組合わせをXPath指定される範囲内においてユニークでなければならないものとして定義することが出来ます。以下に Primerの「5.Advanced Concepts III: The Quartely Report」の例を用いて説明します(長くなるので全体のサンプルはPrimerを参照して下さい)。この例には以下のようなフラグメントが含まれています。

|
|
<一意性指定例>
|
<selector>要素のxpath属性で指定されるXPath表記が、ユニーク指定される対象範囲を定義しています。また、<field>要素は、指定の範囲内でユニークでなければならない要素又は属性を定義しています。上記例では<regions>要素の下位要素<zip>の属性codeは、その範囲内において(すなわちたとえば<regions>要素の下位要素<city>に属性codeが存在しても或いは<regions>要素以外の要素の下位要素<zip>に属性codeが存在しても、それらはユニーク判定の対象にはならないということを意味します)ユニークでなければならないことを示しています。尚、<field>要素を複数指定して複数の要素/定義の組合わせをユニークでなければならないものとして指定することが出来ます。キー参照定義は、ある特定の属性/要素或いはそれらの組合わせをユニークなキー(且つnilであってはならない)として定義することが出来ます。キーの指定の仕方はユニーク指定の場合と同様です。またこのキーに対して<keyref>指定を用いて他の要素からの参照(いわばフォーリンキー)を設定することが出来ます。以下にPrimerからの例を挙げます。

|
|
<キー参照定義例(キー部)>
|

|
|
<キー参照定義例(参照部)>
|
これにより<regions>要素の下位要素<zip>の下位要素<part>の属性numberの値に正確に一致する値をnumber属性として持つ、<parts>要素の下位要素<part>が存在しなければこのスキーマドキュメントにvalidなインスタンスドキュメントではないと見なされることになります(validなドキュメントの例はPrimerを参照して下さい)。
現在Relax NG、Schematron等との比較を検討中。
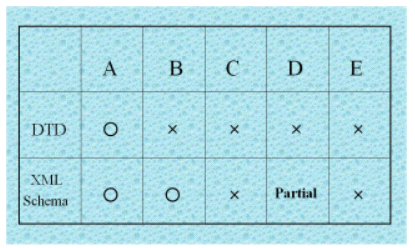
3章で述べてきたように、XML SchemaにはDTDと比較して遥かに豊富な機能が用意されています。しかしながら、現バージョンのXML Schemaでは表現出来ないことも数多く存在することもまた事実です。たとえば、要素間の値の比較や要素出現の条件を指定することは現行のXML Schemaでは出来ません。実際バリデーションの対象となるチェック項目要素は、大きく分けて次の5種類が考えられます。
- ドキュメント構造のバリデーション(マークアップシンタックスのチェック)
- リーフノード(最下位要素)コンテンツのバリデーション(データタイピング)
- 各要素/属性間のシンタックスレベルでの関連に関するバリデーション(たとえば要素Bは要素Aが出現した時にのみ出現するなど)
- 各要素/属性間のコンテンツレベルでの関連に関するバリデーション(キー参照定義など)
- 上記に当てはまらない業務ルールに関連するバリデーション
上記範疇内のみに限って言えば、XML SchemaがDTDよりも優れているのは主にBにおいてであろう考えられます。Aに関しては確かに複合型や派生等の考え方の導入により再利用等の面ではXML Schemaの方が遥かに優れていますが、DTDにおいても機能的にはそれ程大きな問題はなかったものと思われます。CはDTDでもXML Schemaでも現状では定義不可能です。Dに関してはXML Schemaでも一意性指定とキー参照定義があるくらいであり、これはRDB的構造に対応する実践面でのユーティリティ的機能であるとも捉えられ、本当に全てのコンテンツレベルでの関連が網羅されているか否かについては少なからず疑問があります(たとえば要素<MAX>の値は要素<MIN>の値より等しいか又は大きくなければならないというような指定は、キー参照定義などよりも遥かに単純なDに属するバリデーションであると言えますが、現状のXML Schemaにはこれを可能にする手段が用意されていません)。Eに関しては非常に微妙であり、たとえばBやDなどもある意味で業務ルールに関連するバリデーションと言っても良い側面があります。たとえばAのバリデーションに関してエラーが発生したとすると、それはドキュメントを生成するアプリケーションに不備があることが大きく予想されるのに対し、BやDに関するエラーはたとえばオペレータの入力によって発生する業務ルールにも関係し得ると言うことが出来るからです。従ってここではむしろEは、XML SchemaやDTDによる構造記述によっては表現が困難或いは不可能であるような業務ルールチェックであると否定的に定義されるべき項目であるものとします。
ところで、もしXML SchemaがDTDよりも優れている点がB、Dを含めた意味において業務ルールに関連するバリデーションが可能であるということであるとするならば、それがどの程度かということは1つの問題となり得ます(後で述べるようにドキュメントの包括的な文法構造を規定することにアプローチの主眼があるXML Schemaにより、項目Eを完璧に実現することはとても不可能であることが容易に予想されますし、そもそも「XML Schema Part 1: Structures」の「目的」の項に「この仕様によって定義される言語は、あらゆるアプリケーションによって必要とされるあらゆる機能を提供することが意図されているわけではありません。当言語では表現することの出来ない制限機能がアプリケーションによっては必要になることもあるでしょう。その場合にはアプリケーション自身で追加的なバリデーションを実行する必要があるかもしれません。」と明白に記述されています)。ある意味において、たとえば要素間の値の比較などは確かにデータレベルのチェックでありシンタックスレベルに属する問題ではありませんので、必ずしもメタ定義言語であるXML Schemaの対象とする必要はないとも言えるかもしれません。しかしながら、業務ルールを考慮した場合には、要素間の値の比較によるバリデーションなどは日常茶飯に行われていることであり、アプリケーションロジックを組むことなしにそれが可能であれば非常に便利であることに変わりはありません。今後のXML Schema仕様のバージョンアップに期待して、現状で可能なことのみXML Schemaで行い、出来ないことはアプリケーションで補完するというのが一般的なあり方なのかもしれませんが、XML Schemaをアプリケーション以外によって補完する方法がいくつかのインターネットサイトで紹介されています。簡単に紹介しますとまず1つにはXSLTを用いてチェックを行う方法(if testにより判定を行いエラーメッセージをtextとして出力する方法)が挙げられています(後述するSchematronによるバリデーションもこのバリエーションと呼べるでしょう)。もう1つは他のXMLスキーマを併用することが挙げられています。たとえば<annotation>要素の子要素<appinfo>要素中にSchematronのシンタックスを埋め込んでSchematronと併用する例が挙げられています。これに関連して補足しておきますと、XML SchemaはDTDを含め他の多くのXMLスキーマと同様、ドキュメントの全体構造を文法的に包括規定しようとするアプローチがメインになり、3章で述べた機能の多くは文法構造の規定に関わっています。従って業務ルールに関連するチェックを充実させる為には、たとえばキー参照定義のような本来包括的な文法規定とは直接関係のないルール定義機能を個別的に追加していかなければならないことを意味しています。何故ならば業務ルールに関連するチェックとは、ドキュメントの包括的な文法構造には還元出来ないような要素をチェックする場合の方が遥かに多いからです。これに対しSchematronは、そもそも最初からドキュメントの文法構造を包括的な仕方で定義するのが目的では全くなく、個別のチェックルールを局所的に定義しそれを統合していくようなアプローチを取ります(下記例のようにまず個別的にルールを定義することが基本となります)。

|
|
<Schematronスキーマドキュメントのフラグメント>
|
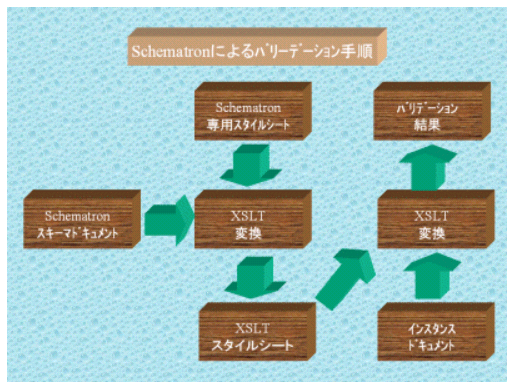
これ故に、業務ルールに関連するチェックという観点から見ればXML SchemaよりSchematronの方が遥かに機能的にフィットする側面があると言えます。この点においてある意味でトップダウン的なアプローチを基本とするXML Schemaをボトムアップ的なアプローチを基本とするSchematronで補完することの有効性が強調されているわけです。尚補足しておきますとSchematron自体はXSLTによる2度変換(すなわち作成したSchematronスキーマドキュメントをSchematronで用意されている専用XSLTスタイルシートで変換し、その出力XSLTスタイルシートを使用して更にもう一度インスタンスドキュメントに対しXSLT変換を適用するという手順になります)で実装出来ますので、Schematronを補完スキーマとする場合には前述したように第一の方法のバリエーションとも言えるかもしれません。
勿論XML SchemaはJavaでなければ利用出来ないということはありませんが、オブジェクト指向言語としてのJavaの有するXMLとの親和性を考慮して現状におけるJavaにおけるXML Schema対応について簡単に記述しておきます。SUN Microsystems社は、Javaを利用したXMLハンドリングに関していくつかのインターフェース仕様(及びそのリファレンスインプリメンテーション)を公開していますが、その最もベーシックなものはJAXP仕様であると言えます。しかしながら現行バージョン(JAXP 1.1)の段階においてはXML Schemaに関するインターフェース定義はこの中には含まれていません。従って現状では、たとえXMLパーサ等のXMLアプリケーションがXML Schemaをサポートしている場合でも、それは完全に実装に依存した方法に依拠しており、たとえばエラーのハンドリング方法なども実装任せという状況になっています。たとえばXercesパーサには既にXML Schemaを利用したバリデーション機能が含まれていますが、実際の業務で利用するにはエラーハンドリング等に問題がないとは言えない状態です。たとえばメッセージによってしかエラーの違いが認識出来ない、或いは最初のバリデーションエラーが検出された段階でExceptionが発生するために全てのエラーを一度に把握することが出来ない等です。このような問題は、JAXP等の共通仕様により標準的なハンドリング方法が確立されることによってある程度解決される問題でもあるように思われますので(メーカ毎に都合のよいインターフェースが採択出来なくなる為)、スキーマドキュメントのハンドリングに関する標準仕様の決定が待たれるところでもあります。
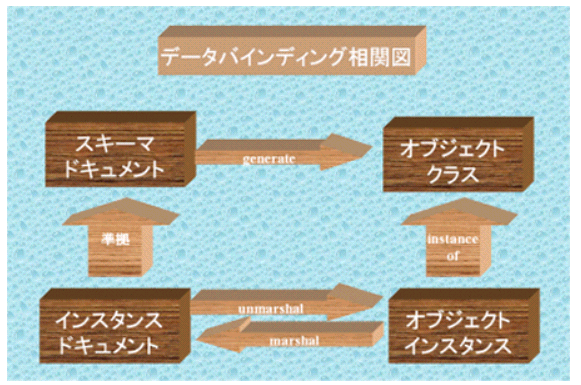
XML Schemaを利用した応用機能は現状でもバリデーション等いくつか考えられますが、ここではその1つであるデータバインディングをXML Schemaの応用例として取り上げてみたいと思います。データバインディングとはXMLインスタンスドキュメントをシームレスにメモリオブジェクト(或いはDB等)にマッピング展開する方法(unmarshal)及びその逆展開(marshal)を行う方法を言います。このデータバインディングにおいてXML Schemaが有効である理由は、個々のインスタンスドキュメントの共通構造を記述するのがXML Schemaによるスキーマドキュメントであり、XMLインスタンスドキュメントとXMLスキーマドキュメントの関係をオブジェクト指向におけるインスタンスとクラスの関係に射影することが出来るという点にあります。すなわちXML Schemaのスキーマドキュメントファイルを入力として、たとえばJavaであれば対応するJavaクラス(marshal,unmarshalメソッドがクラス内に自動生成され、生成元のスキーマドキュメントによりvalidであることが保証されるインスタンスドキュメントとインスタンスオブジェクト間でのデータ交換がこれらのメソッドにより可能となります)を出力するようなジェネレータがあれば、いちいちDOMやSAXレベルのAPIを用いてインスタンスドキュメントの処理を行うアプリケーションを作成する必要がなくなります。このデータバインディングの実例として、Javaで言えばSUN Microsystems社によって提唱されているJAXB仕様が典型例として挙げられますが、現状では残念ながら独自のXMLシンタックスを定義しているようであり、XML Schemaは対象となっていません(仕様には、将来バージョンではXML Schemaの一部の機能をサポートするとあります)。それ以外でも何らかの形でデータバインディングを実装しているアプリケーション或いはアプリケーションサーバはいくつかあるようですが、ここではその1例としてオープンソースプロジェクトのCastorを紹介します。CastorはJavaをターゲットとしたデータバインディングフレームワークであり、フレームワーク自体のJavaソースコードを含めて以下のアドレスhttp://www.castor.orgより誰でも自由にダウンロードすることが出来ます。
Castorには2つのバインディング方法が用意されています。1つはスキーマレスバインディングと呼ばれるバインディングで、この方法ではXML Schemaは用いられません(従ってここでは説明しません)。もう1つがXML Schemaを利用したバインディングです。ここでは、実例(unmarshal例)を用いてこのXML Schemaを利用したバインディングを説明します。まず以下のような<person>要素と<address>要素を定義するスキーマドキュメントがあったとします。

|
|
<入力スキーマドキュメント例>
|
このスキーマドキュメントをCastorで用意されているジェネレータに入力すると、PersonクラスとAddressクラスという2つのJavaクラスが生成されます。以下は生成されたPersonクラスの例です(若干のメソッドを省略してあります。また、Addressクラスは紙幅の関係で省略します)。

|
|
<生成Javaクラス例>
|
上記例においてmarshalメソッド及びunmarshalメソッドが自動生成されている点に注意して下さい。これらのメソッドに対しては、アクセスするインスタンスドキュメントに対するWriter(marshalの場合)或いはReader(unmarshalの場合)をパラメータ指定することが出来ます。ここで、上記スキーマドキュメントにvalidである以下のようなインスタンスドキュメントperson.xmlがあるものとします。

|
|
<入力インスタンスドキュメント例>
|
このスキーマインスタンスを読込むには以下のようなコードを書くだけで済みます。

|
|
<生成されたJavaクラスを利用するAP例>
|
上記例のunmarshalメソッドはFileReaderの入力パラメータとして指定されているインスタンスドキュメント(person.xml)を読込み該当クラスのインスタンスオブジェクトを生成しそれをAPに戻します。従って、インスタンスドキュメントを処理するアプリケーションはDOM、SAX等のAPIを用いることなくインスタンスドキュメントへのアクセスを行うことが出来ます。尚、上記例は非常に単純なJavaアプリケーションを利用した例ですが、応用としてたとえばアプリケーションサーバコンテクスト内にデータバインディング機能を用意しておいて、たとえば外部システムとSOAPによりデータ交換を行うケースなどにおいて、SOAPでやり取りする入出力メッセージの構造をXML Schemaで記述しておいて(但しXSLT等で補完する必要があるかもしれません)アプリケーションの仲介なしにSOAPメッセージ<−>メモリオブジェクト間のシームレスな変換を実現する等の利用形態も考えられるでしょう(尚、このCastorはアプリケーションサーバではありませんのでそのような機能は有していません)。
オブジェクト指向の考え方がコンピュータ業界に広く浸透するにつれて、それにより「抽象と実装の分離」の考え方をシステム内に応用することが現実的に可能になりました。この「抽象と実装の分離」の考え方は、ある意味においてシステムを標準化するとはどういう意味かということを明確に定義付けたと言ってよいかもしれません。またこのような流れは、単にコンピュータ業界内のみに特異な現象であると言うよりも、ある程度社会的な要請にも深く関わっているものと言えます。たとえば、イギリスの社会学者アンソニー・ギデンズは「高度なreflexivity」というような言い方によって現在という時代の持つ特徴を表現しています。これはすなわち、一般大衆レベル(コンピュータ業界で言えばコンピュータシステムのユーザ)のリテラシーが向上するにつれて、計画立案者(コンピュータ業界で言えばシステムインテグレータ)は前もって全ての事象を考慮に入れてプランを立てること(コンピュータ業界で言えばシステムを構築すること)はますます困難になるであろうということを意味しています。何故ならば、リテラシーの向上に伴い、ユーザは本来計画の意図には含まれていなかったような仕方である特定の計画の実装を利用したり、更にリテラシーが高度化するとユーザの方が計画立案者が計画するであろうプランを予め予想した上で一定のカウンターメジャーを独自にいち早く創出したりするからです。こうなると計画立案者は、自分が立てた計画が齎す効果或いはそれに対するユーザ側の予想を更に先取的に予想し計画を立案する必要が生じるわけです。すなわち現代という時代においては単純に一次元的な計画モデルは通用しないということを意味し、その1つの実例としてギデンズはソビエトの社会主義経済崩壊の一因をこの点に求めています。
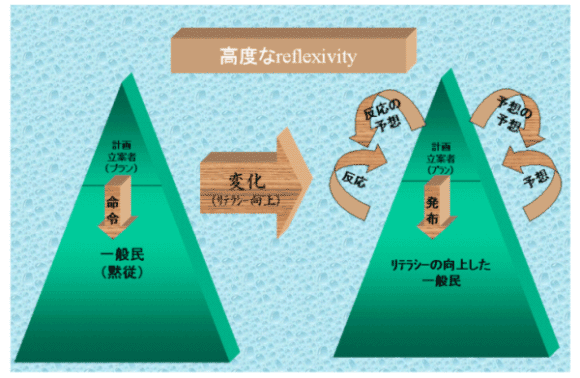
勿論それとは別に急速な技術革新による実装レベルでのシステム更新の必要性、或いは今後は頻繁に発生するであろう異業種異システム間でのシステム統合の必要性等に関連して必要となるであろう要件を全て事前に把握することは最早不可能に近いと言ってよいでしょう。コンピュータサイエンティストのリチャード・ガブリエル氏などはこのような時代においては初めから全ての要件を織り込んだ大伽藍のようなシステムを構築することは不可能になりつつあると述べています。それならばどうすべきかということを考えると、システムの内部においてもコンテクストが変化するにつれて変化する部分(実装)と、コンテクストの変化により影響を被ることの少ない部分(抽象)を明確に分離することが非常に重要な意味を持つことに気付くことが出来ますが、近年におけるオブジェクト/コンポーネント指向の普及が可能にしてきたことの1つがまさにコンピュータシステムという分野におけるその実現であったことは言うを待たないところです。また、このような抗い難い社会的な要請の流れの中で近年登場してきた技術の1つがXML(オペレーションシステムというコンテクストが異っても有効であるようなデータ表現方法)であり、またXML Schema(ある特定のデータ構造の汎用的表現手段)であると言うことが出来るように思います。従って、これらの技術は単に便利な道具として偶然の産物として誕生したというよりも、大袈裟な言い方をすればある意味で歴史の必然として誕生したものとして把握されるべきであるように思います。勿論インフラとしてのインターネット、HTTP、HTML等の成立普及という要因も挙げなければなりませんが、昨今のXML隆盛の基盤にも明らかにこのような抽象の分離という意味でのシステム標準化の考え方があることを理解する必要があるでしょう。このような流れを考慮に入れると、特定のOSやDBMSによって表現構造が変ったりすることのないXMLにより記述されるデータ構造を、人間に対してのみならずマシンに対しても明確に表現伝達することが出来るXML Schemaが今後もより重要な位置を占めていくであろうことが十分に予想され、今後の動向がますます注目されます。
Copyright c XMLコンソーシアム 2002 All rights reserved.
Copyright c 情報技術開発株式会社
2002 All rights reserved.
利用条件
本書は、本書の内容及び表現が変更されないこと、および出典を明示いただくことを前提に、無償でその全部または一部を複製、転記、引用して利用できます。なお、全体を複製された場合は、本書にある著作権表示および利用条件を明示してください。
本書の著作権者は、本書の記載内容に関して、その正確性、商品性、利用目的への適合性等に関して保証するものではなく、特許権、著作権、その他の権利を侵害していないことを保証するものでもありません。
本書の利用により生じた損害について、本書の著作権者は、法律上のいかなる責任も負いません。