Web上で公開されているWebAPIを利用したマッシュアップ・アプリケーションの例を取り上げてみる。
Webブラウザを使って複数のREST型Webサービスを呼び出し,そこで得られた情報を基に,マッシュアップした内容を表示するアプリケーションを組んでみる。 節 2.1 で紹介するマッシュアップの例は,XML,XSLTを利用しているので,以下ではXSLTマッシュアップと呼ぶことにする。ここに示す例では,WebブラウザとしてIE6を想定しており,他のブラウザではうまく稼動しない。XSLTプロセッサを用いて,予めHTMLに変換しておくことによって,他のWebブラウザでもみえるようになる。また,IE6においても, ポップアップを許可すること,異なるドメイン間へのアクセスを許可すること が必要となるので,閲覧,実行する際には,注意されたい。
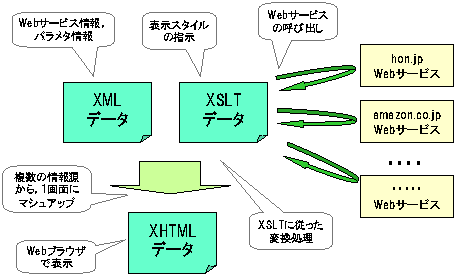
ここに紹介するXSLTマッシュアップでは,マッシュアップに関わるWebサービスの情報,パラメタなどの基礎的なデータをXMLで保持し,そのXMLに関連付けたXSLTによって,REST型Webサービスを呼び出し,HTMLにまとめる形を採用することによって,簡単にマッシュアップ・アプリケーションができる。
XSLTマッシュアップでは,XSLTによる変換処理をどこで行うかによって,クライアント変換型とサーバー変換型の2つの種類がある。クライアント変換型のXSLTマッシュアップでは,WebサイトからXMLをダウンロードして,WebブラウザのXSLT変換処理を利用する。一方,サーバー変換型のXSLTマッシュアップでは,Webサービスの呼び出し時に変換指示用のXSLTを指定して,サーバー側でXSLT変換を行う。
複数のWebサービスをマッシュアップする際に,Webサービスの連携の仕方によって,並列型と直列型がある。複数のWebサービスを順に呼び出し,その結果をマッシュアップする形態を並列型マッシュアップ呼ぶ。もう1つの形態である直列型マッシュアップは,1つのWebサービスを呼び出して,その応答メッセージからあるキーワードを抽出し,それを手掛かりに別なWebサービスを呼び出して,その結果をマッシュアップするという形態である。直列型では,はじめに呼び出したWebサービスの結果によって,それ以降のWebサービスが呼び出されるために,結果として得られるデータの意外性が生じやすい。 節 2.1 で扱うWebサービスの種類とその内容について以下の 表 1 , 表 2 に示す。
項 2.1.2 に示す例では,クライアント変換型の直列型XSLTマッシュアップであり, 項 2.1.3 の例では,サーバー変換型の直列型XSLTマッシュアップである。利用するWebサービスを 表 1 に示す。
| サービス | 内容 | 備考 |
|---|---|---|
| hon.jp | 電子書籍の検索 | hon.jpの電子書籍メタデータDBの内容を取得 |
| amazon.co.jp | 書籍の検索 | amazon.co.jpの書籍情報の内容を取得 |
項 2.1.4 のWebサービスの例では,クライアント変換型で,直列型と並列型を混合させた形態である。利用するWebサービスを 表 2 に示す。
| サービス | 内容 | 備考 |
|---|---|---|
| kanzaki.com | 写真のメタ情報獲得 | 写真のメタデータをRDFとして獲得する |
| ウェザーハックス | お天気情報獲得 | 今日,明日,明後日の天気情報の取得 |
| グーグルマップ | 地図情報 | 位置情報を元に地図を表示 |
| hon.jp | 電子書籍の検索 | hon.jpの電子書籍メタデータDBの内容を取得 |
| じゃらんWebサービス | 宿・ホテル情報獲得 | 宿表示API ライトを利用 |
はじめにクライアントサイドでXSLT変換を行う例を紹介する。利用するWebサービスとしては,hon.jp (http://hon.jp/)で提供される電子書籍の情報サービス及びアマゾン(http://amazon.co.jp/)で提供される書籍情報の2種類である。利用者からhon.jpの情報提供サービスを用いて,キーワード検索をし,電子書籍を5冊リストアップし,そのうち書籍として発行しISBNがあるものは,アマゾンの書籍情報サービスを利用して表紙の画像を得て,詳細情報にリンクを張るという内容である。
入力となる情報をXML(以下,入力XML)として作成し,それに対するスタイルシートをXSLTで作る。XSLTの内容はWebブラウザで表示させるべくHTMLに変換する指示を記述している。Webブラウザ上で2種類のWebサービスから得た情報をマッシュアップして表示するという簡単な仕掛けである。
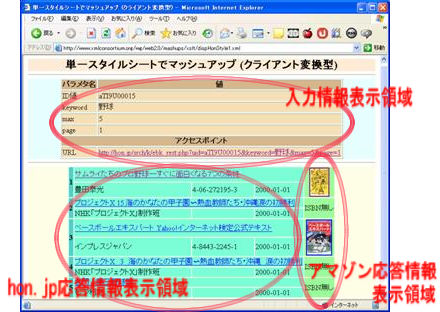
この例では,入力XMLの中に,利用者の希望する検索キーワードを指定するようになっており,利用者の任意の語を設定できる。この入力XMLを利用者の望む形で作成するインタフェースを設けることによって,より実用的なアプリケーションとすることができる。ここではXSLTを利用したごく簡単なマッシュアップの例( 図 2 参照: dispHonStyle1.xml )を紹介する。
入力となる情報は,検索のためのキーワード(この例では「野球」),一回の要求で表示する最大件数(5件),件数が多いときにページが分割されるため,そのページ番号(この例では一ページ目)という情報であり,これを入力XML(ファイル名:dispHonStyle1.xml)として定義する。hon.jpのWebサービスを利用する場合には,アクセスのためのIDが必要となるので,この値もこの入力XML内に指定しておく。各自で実際に試す場合には,是非自分用のIDを取得して使っていただきたい。 図 2 の画面上では上部に入力XMLの内容を表示させている。ここでのIDは,お試し用IDを使用している。
<hon:hon xmlns:hon="urn:hon">
<hon:baseUrl>
<hon:honBaseUrl href="http://hon.jp/rest/1.0/"/>
<hon:xsltBaseUrl href="http://www.xmlconsortium.org/wg/web2.0/mashups/xslt/"/>
</hon:baseUrl>
<hon:ids>
<hon:honUserId>aRUIO00003</hon:honUserId> ←本運用までのお試し用IDを使用
</hon:ids>
<hon:stylesheet>
<hon:style>
<hon:description xml:lang="ja">
単一スタイルシートでマッシュアップ (クライアント変換型)
</hon:description>
</hon:style>
</hon:stylesheet>
<hon:params>
<hon:param name="keyword" value="野球"/> ←キーワードの指定
<hon:param name="max" value="5"/> ←1ページ内件数の指定
<hon:param name="page" value="1"/> ←ページ番号の指定
</hon:params>
</hon:hon>この入力XMLに対して,スタイルシート(XSLT,dispHonStyle1.xsl.xml)を用意して,まずは画面の上部に入力の内容を示す表(table)を生成する指示を記述する。その後でhon.jpのWeb APIを呼び出し,電子書籍の情報を獲得し,表の下部左側部分の各セルに対応する情報を埋め込む。
次のXSLTのコード( コード 2 )は,入力XMLで指定されるhon.jpのWeb APIを呼び出すURLの定義と実際に呼び出す部分である。ベースとなるURLの後に,利用者ID(uid)を付け,xsl:for-each命令を使ってパラメタとなるキーワード,最大件数,パージ番号を巡回的に付加してアクセス用のURL(accessUrl)を定義している。そして3段落目がそのURLを使って,Webサービスを呼び出すコードである。hon.jpのWeb APIはREST型のWebサービス呼び出しであり,HTTPのGETを利用しているために,XSLTでは,document関数を使って,そのWeb APIを呼び出すことが可能な点に注目して欲しい。
<xsl:variable name="honBaseUrl" select="/hon:hon/hon:baseUrl/hon:honBaseUrl/@href"/>
<xsl:variable name="accessUrl">
<xsl:value-of select="$honBaseUrl"/>
<xsl:value-of select="/hon:hon/hon:params/hon:param[@name='keyword']/@value"/>
<xsl:text>/</xsl:text>
<xsl:value-of select="/hon:hon/hon:ids/hon:honUserId"/>
<xsl:text>/</xsl:text>
<xsl:for-each select="/hon:hon/hon:params/hon:param[@name!='keyword']">
<xsl:if test="position()!=1">
<xsl:text>&</xsl:text>
</xsl:if>
<xsl:value-of select="@name"/>
<xsl:text>=</xsl:text>
<xsl:value-of select="@value"/>
</xsl:for-each>
</xsl:variable>
<xsl:variable name="honjpDoc" select="document($accessUrl)"/>この結果,Web APIで呼び出された情報は,XSLTの中では,"honjpDoc"という名前のドキュメントノードとして取り扱うことが可能となる。ここで応答として得られるXMLの中身については,hon.jpのサイトにあるドキュメントを参照して分かるように,ルート要素を"ProductInfo"として持ち,その子要素として,1個の"request"及び複数個の"results"などの要素を持つ構造をしている。results要素が1つの電子書籍の情報を持つ。因みにresults要素は,最大件数を5に設定したために,ここでは5個以下のはずである。hon.jpからの応答XMLが具体的にどんな内容かを確かめるために,上記のアクセス用URLを実際に手作業で作りあげ,Webブラウザ上で呼び出してみるとよくわかる。
http://hon.jp/rest/1.0/野球/aRUIO00003/max=5&page=1
↑IDとして本運用までのお試し用IDを使用このリクエストによって,応答されたXMLを見ながらXSLTのコード作成などを作成すると良い。このURL上ではキーワードが漢字表記されているが,Webブラウザ(IE6)上では,エスケープされてアクセスされるためにこのままでも良い。
このhonjpDocのノードの中で現れる要素"ProductInfo"を取り出し,XSLTのテンプレートを適用させるためには,次の様に,XSLTのxsl:for-each命令を使うことで達成される点を注目したい。
<div class="result">
<xsl:for-each select="$honjpDoc">
<xsl:apply-templates select="ProductInfo"/>
</xsl:for-each>
</div>そして"ProductInfo"に対するテンプレートの中で,各results要素を取り出し,必要な情報をHTMLの表(table)に変換するコードが, コード 5 である。
<xsl:template match="ProductInfo">
<table>
<xsl:for-each select="results">
<xsl:apply-templates select=".">
<xsl:with-param name="nbr" select="position()"/>
</xsl:apply-templates>
</xsl:for-each>
</table>
</xsl:template>
<xsl:template match="results">
ここにresults要素の記述をする
</xsl:template>"results"要素に対するテンプレートの中における1件分の処理の最後で, 図 2 の下部右側部分にアマゾン提供の画像情報を埋め込むための考慮をしておかなければならない。honjpDocノード内にあるISBN(sourceISBN_10要素)をキーとして,更にアマゾン提供のWeb APIを使って書籍データを獲得するために,またアマゾンWebサービスへのアクセス用のURLを作成しなければならない。 コード 6 では,最初の段落で情報の区切りごとに設定するコードを示している。各パラメタは,amazon.co.jpのWebサービスの規定に従って記述しなければならない。ISBN番号からハイフンを除いたものが,ItemId要素であるために,XPathのtranslate関数を使って,sourceISBN_10要素の中身からハイフンを削除している点に注意。
<xsl:variable name="amzonIsbnCallUrlBase">
<xsl:text>http://webservices.amazon.co.jp/onca/xml</xsl:text>
<xsl:text>?</xsl:text><xsl:text>Service=AWSECommerceService</xsl:text>
<xsl:text>&</xsl:text><xsl:text>Version=2007-02-22</xsl:text>
<xsl:text>&</xsl:text><xsl:text>AWSAccessKeyId=ここにID情報を記述</xsl:text>
<xsl:text>&</xsl:text><xsl:text>Operation=ItemLookup</xsl:text>
<xsl:text>&</xsl:text><xsl:text>ResponseGroup=Medium</xsl:text>
<xsl:text>&</xsl:text><xsl:text>IdType=ASIN</xsl:text>
<xsl:text>&</xsl:text><xsl:text>ItemId=</xsl:text>
</xsl:variable>
<xsl:variable name="awsAccessUrl">
<xsl:choose>
<xsl:when test="sourceISBN_10 != ''">
<xsl:value-of select="$amzonIsbnCallUrlBase"/>
<xsl:value-of select="translate(sourceISBN_10,'-','')"/> ←ハイフンの削除
</xsl:when>
<xsl:otherwise/>
</xsl:choose>
</xsl:variable>
<xsl:variable name="ansXml" select="document($awsAccessUrl)"/>そして,XSLTのdocument関数で獲得したWebサービスからの応答メッセージを,ansXmlという名前でドキュメントノードとして保持しておく。アマゾンWebサービスの情報から,画像情報を取り出す部分のコードは コード 7 の通り。
<xsl:variable name="imgUrl"
select="$ansXml/aws:ItemLookupResponse/aws:Items/aws:Item/aws:SmallImage/aws:URL"/>
<img src="{$imgUrl}"/>画像情報のURLを取り出すだけなので,XSLTでは,ドキュメントノードを示す$ansXml変数を使って,変数imgUrlの値として簡単に取り出せる。HTMLのimgタグのsrc属性にこの値を設定すれば,Webブラウザ上で表紙の画像が表示される。 XML,XSLTをダウンロードして,入力用XMLのデータを変更してみて,Webブラウザ(IE6)で見ることで是非確かめて欲しい。もう少し複雑な利用法や,パラメタを入れ替えて,複数のスタイルで見ることも可能になっているので, 項 2.1.5 を参照していただきたい。
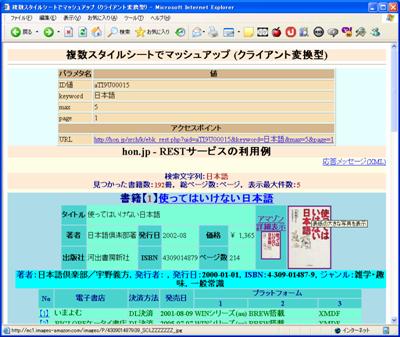
図 3 の例( dispHonStyle2.xml )は, 図 2 とほぼ同様の処理をしているが,XSLTを分割して,xsl:import処理をしているところが異なっている。入力XMLを処理するXSLTから,hon.jpからの応答XMLを処理するXSLT( hon-style-01.xsl.xml )をインポートし,更にそのXSLTから,アマゾンWebサービスからの応答XMLを処理するXSLT( amazonIsbn2.xsl.xml )とから構成されている。それぞれのXSLTが,単独でそれぞれの応答XMLを処理するように作成されているおり,それらを,再利用する形となっている。
hon.jpのWeb APIでは,パラメタの1つとしてXSLTを指定しサーバー側でXSLT変換をさせる方法も可能となっている。Web APIでのリクエスト時にXSLTソースのURLを指定することにより,サーバーサイドで変換を行いWebブラウザにはHTMLとして応答するために,XML,XSLTを直接支持しないWebブラウザでも利用できるところが便利である。但し,サーバーサイドでのXSLTプロセッサの能力によって,現実的にはすべてのXSLTの機能が使えるわけではないので注意する必要がある。また,サーバーサイドからURLを介してXSLTのソースを獲得しようと試みるため,XSLTソースは公開されていなければならない。従ってローカルなPC上にあるXSLTファイルを利用することはできず,公開サーバーの上に配置したXSLTファイルを使用しなければならない。
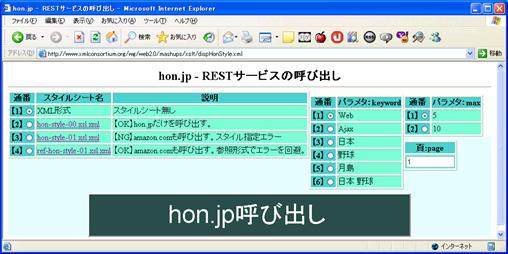
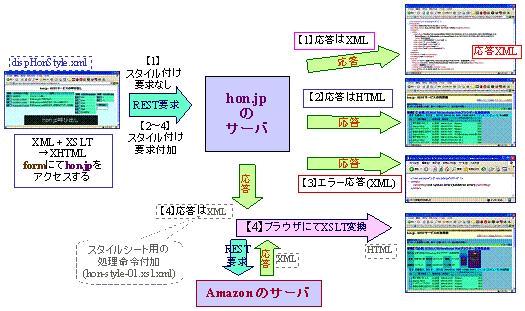
図 4 は,サーバーサイドでXSLT変換を行わせるために用意した画面( dispHonStyle.xml )である。
図 4 は,hon.jpのREST型WebAPIを呼び出すためのパラメタ設定を画面上から選択させ,その応答に対してどのスタイルシートを適用させるかを指定するために,HTMLのform機能を用いて作成したものである。左端の通番欄のスタイルをチェックし,右側のパラメタを選んで,「hon.jpの呼び出し」ボタンをクリックすることによって,hon.jpにアクセスする。このソースは,XMLであり,パラメタとなる候補群を予め設定するようになっている。スタイルシート( dispHonStyle.xsl.xml )では,そのXMLの内容をformを使うHTMLに変換している。ここでは4通りのスタイルを指定しているが,【1】はスタイル変換をしない指定であるため,パラメーターに応じて要求された応答としてのXMLが表示される。そのほかどんな形で変換しているかを概観したのが 図 4 である。
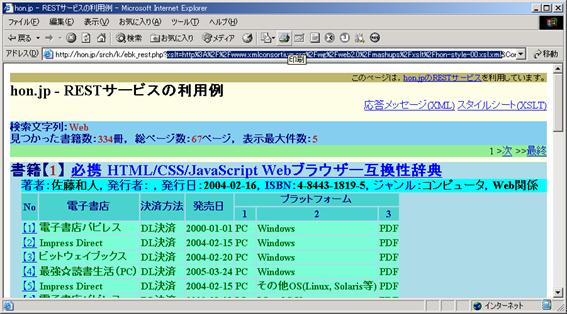
【2】は"hon-style-00.xsl.xml"というスタイルシートを選択するものである。このXSLTは単独のファイル構成であり,xsl:import命令やXSLTのdocument関数を使用してはいない。ここで【2】をチェックしてから,下部のボタン「hon.jp呼び出し」をクリックすると,サーバーサイドによるXSLT変換が指示できる。結果の画面は, 図 6 となる。
この画面において,上部にあるWebブラウザのアドレス欄を良く見ると,「xslt=http%3A%2F%2F・・・%2Fhon-style-00.xsl.xml」という文字列を含んでいることがわかる。URLを示す文字列では,「%xx」は16進表現された文字コードを持つ文字であることを意味するので,「xslt=http://・・・/hon-style-00.xsl.xml」ということであり,XSLTファイル(hon-style-00.xsl.xml)を指定して,サーバーサイドでXSLT変換をすることを指定していることになる。その応答結果は,HTMLであり,そのHTMLがそのままWebブラウザで表示されている。
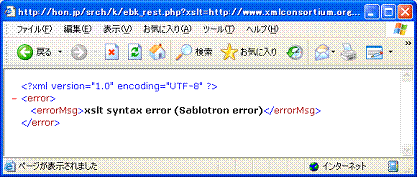
図 4 で,【3】をクリックし,hon.jpを呼び出すと,XSLTファイル( hon-style-01.xsl.xml )を指定して,Webサービスを呼び出してみる。その結果はエラーとなりエラーメッセージを含む応答XML( 図 7 )が返される。このメッセージでは,XSLTでの構文エラーであるこを示している。つまりサーバー側でのXSLT変換ができないということである。
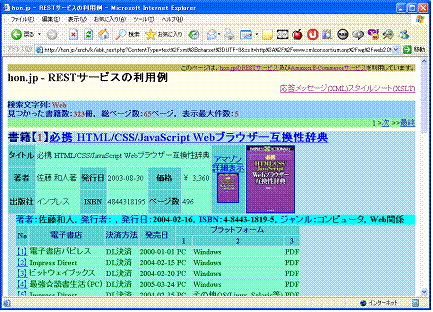
ここで指定したXSLTスタイルシートは, hon-style-01.xsl.xml であり,先に紹介したクライアントサイドXSLTマッシュアップの2番目( 図 3 )の最下部に表示されているスタイルと同一である。インポート先のXSLTファイルの中でdocument関数を使っているのが,エラーの原因のようである。このエラーを回避するために, 図 4 の【4】を設けた。【4】では,Webサービスへの要求に対して応答されるXMLに,単純にXSLT指定( hon-style-01.xsl.xml )を指示するの処理命令( コード 8 )を付加するだけとした。
<?xml-stylesheet type="text/xsl" href="・・・/mashups/xslt/hon-style-01.xsl.xml"?>その処理命令を生成するXSLTソースが コード 9 (ref-hon-style-01.xsl.xml)である。
<xsl:template match="/">
<xsl:processing-instruction name="xml-stylesheet">
<xsl:text>type="text/xsl" </xsl:text>
<xsl:text>href="http://・・・・・/hon-style-01.xsl.xml"</xsl:text>
</xsl:processing-instruction>
<xsl:copy-of select="."/>
</xsl:template>このスタイルシートを使うことによって,スタイルシートの引用指示をする処理命令が挿入されたXMLがWebブラウザに応答され,Webブラウザ側の処理でHTMLに変換されることになる。 図 4 の【4】ではこの方法を使っている。【4】にチェックを入れ,「hon.jp呼び出し」のボタンをクリックし,その結果をIE6で表示したものが 図 8 である。
この方法を使って,現状では IE6で表示できているが,Firefox2.0では,XMLがテキストとして処理されているため,期待に反した表示になっている( 図 9 )。一旦,ローカル環境にXMLを保存し,改めてそのXMLを表示させるとうまく見えるようになるはずである。
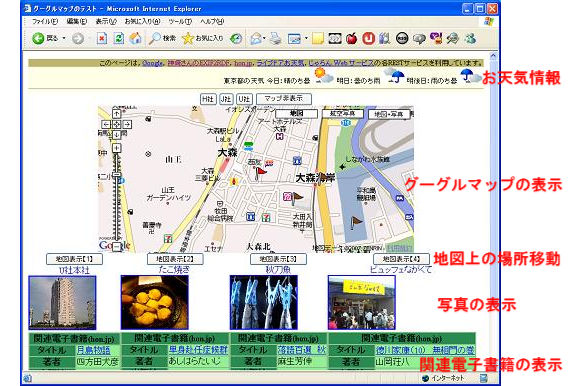
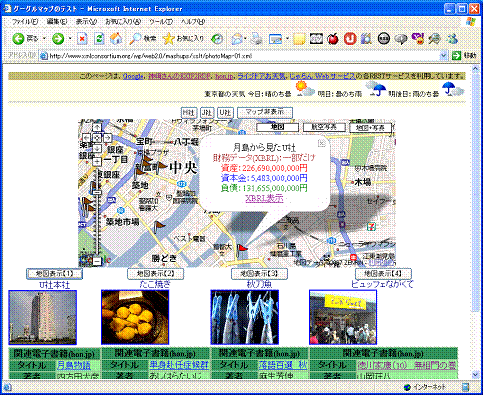
次にグーグルマップを利用したもう少し複雑な例を紹介する。まず 図 10 の画面を見ていただきたい。
このWebページでは,中央部に地図が表示されており,そのすぐ下に4種類の写真が配置されている。更にその下方にその写真に関連した電子書籍の情報が出ている。画面の最上部には,このページを閲覧したときのその地域(東京)でのお天気情報が出ており,この日以降は,段々と天気が崩れていきそうなことが読み取れる。
様々な情報が1つの画面に現れているが,その元になるのは,1つのXMLファイル(入力XML, photoMap-01.xml)に指定されたデータである。右端の写真に関する情報は, コード 10 のように記述されている。
<photo href="http://・・・・/mashups/xslt/photos/nagakute.jpg">
<title>ビュッフェながくて</title>
<description flagIconUrl="・・・・/mashups/xslt/images/flag2_green.png">
<html:span style="color:red;">ビュッフェ ながくて</html:span>
<html:br/>
<html:span style="color:blue;">
>今は<html:em>記念公園</html:em> になっているぞ!</html:span>
</description>
<keywords>
<keyword>長久手</keyword>
</keywords>
</photo>ここでは写真の在り処(URL)と,タイトル,説明用の記述及びキーワードの情報だけが指定されている。説明記述内には,名前空間の接頭辞として,”html”を付加した,HTMLタグが指定してあるため,少し複雑になっているが,テキストと,強調,色などのスタイルを指定している例である。
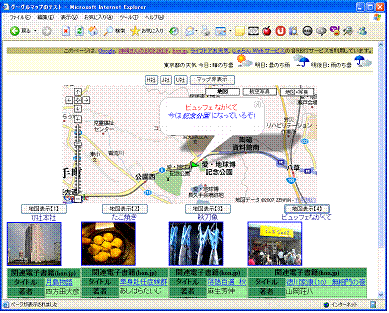
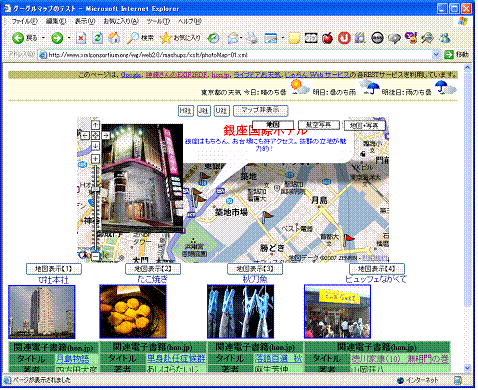
ここで, 図 10 の写真の上にある「地図表示【4】」と書かれたボタンをクリックすると,次の様に変化する。まず中央の地図として愛・地球博記念公園(愛知県長久手)付近が表示される。この中央にある黄緑の旗のアイコンをクリックした後の状態が 図 11 に表示されている。出現した吹き出しの中に,先ほど指定した入力XML( コード 10 )に指定されている説明の内容が,色つきで,しかも「記念公園」が強調されて斜体になっていることがわかる。
この写真は平成17年春から夏にかけて開催された愛知万博「愛・地球博」の会場で撮った写真である。そのときに撮影した場所が,地図上でこの緑の旗が置かれている場所だったのだ。現在は,愛・地球博 記念公園になっていることがこの地図から発見できる。
この同じ写真(右端)の下には,「徳川家康(10) 無相門の巻」という電子書籍の情報が出ている。どうしてこのような情報が出ているかと言うと,先ほどの入力XMLデータ( コード 10 )中にあるキーワード「長久手」から,hon.jpで提供されている電子書籍のWebサービスを検索した結果を表示しているからだ。電子書籍のタイトルの部分をクリックして,そこに張られているリンク先(hon.jpサイト)を見ると,「長久手の地に、秀吉と家康は宿命の対陣に。和睦の条件は家康の次男を秀吉の養子にすること…。」と解説が出ている。この文があるために,キーワード「長久手」が検索で見つかったものと考えられる。
写真情報と長久手というキーワードを基にして,地図情報とそれに関連する電子書籍情報とが結びついて,江戸時代にこの地で徳川家康が関係していたのだと言う知識までを,このマッシュアップで知ることができたことになる。このように異なるWebサービスをマッシュアップした効果によって,当初は思いも付かない情報が得られたという経験を持つことができたと考えられる。
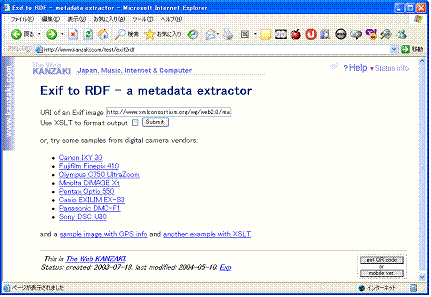
最初に与えた入力XMLデータ中( コード 10 )に,愛知万博での撮影場所は,明示的には指定していないのにどうして位置がわかったのであろうか。その仕掛けはこの写真にある。この写真はGPS付き携帯で撮ったものであり,写真(JPEGファイル)中に位置情報を持っている。そのためその位置情報を取り出すことによって,位置がわかる。JPEG中には,EXIFと呼ばれる形式によって情報が記述されている。それを取り出すために,この例では「Exif to RDF」というWebサービス( http://www.kanzaki.com/test/exif2rdf )を利用している( 図 12 )。
このサイトでは,HTMLのformによって,写真のURLを入力すると,RDFを返してくれることになっている。RDFというのは,メタデータを表現するXMLデータである。このRDFでは,この写真に関する様々なメタデータを持っている。XSLTマッシュアップの例では,その中から位置情報だけを利用させて頂いている。 位置情報を含む部分を示す( コード 11 )。
<foaf:Image rdf:about="http://www.xmlconsortium.org/wg/web2.0/mashups/xslt/photos/nagakute.jpg">
<dc:date>2005-05-15T11:52:22</dc:date>
<dpd:generated rdf:parseType="Resource">
<geo:lat>35.1762194444</geo:lat>
<geo:long>137.085819444</geo:long>
</dpd:generated>
<exifdata rdf:resource="#Primary_Image" />
<exifdata rdf:resource="#Thumbnail" />
</foaf:Image>この中で geo:lat と geo:long 要素が経度・緯度による位置情報である。この値を取り出して,グーグルマップ上にその位置を表示するようにしている。
次に, 図 10 に戻って,「地図表示【1】」と書かれた写真を見る。この写真は豊洲にある会社(U社本社)の近くから撮った写真である。「地図表示【1】」のボタンをクリックし,地図中央の赤い旗のアイコンをクリックしたときの状態が 図 13 である。
グーグルマップ中の吹き出しの中には,財務データ(一部)が記されている。この財務データは,XBRL形式で表現されており,その一部を取り出して編集した形で,欲しい情報を見ることができる。このXBRLデータは,正式に公開されているものではなく,筆者がテスト用に作成したものである。平成20年4月以降には,金融庁が提供するEDINETにて,XBRLにて正式に公開される予定なので,それらを利用することによって,取引企業の財務情報などを簡易に利用することが可能になるはずである。
XBRLの情報を得るために,最初に与える入力XMLには, コード 12 のような情報を与えている。具体的には,1つ目のinfo要素にて,XBRLであることの型の定義とXBRLデータのURLの指定している。XBRL情報を,吹き出し中に表示するためのXSLTは,ここでは説明しないが,興味ある人は,XSLTからインポートされるXSLTスタイルシートを参照していただきたい。
<photo href="・・・・/mashups/xslt/photos/uBuild.jpg" label="U社">
<title>U社本社</title>
<description>
<html:div>月島から見たU社</html:div>
<html:div style="color:brown;">財務データ(XBRL):一部だけ</html:div>
</description>
<keywords>
<keyword>月島</keyword>
</keywords>
<extrainfo>
<info type="xbrl-bs2" url="・・・・/xml/xbrl/bs-NUL061-xbrl.xml"/>
<info type="jalanHotel"
url="http://jws.jalan.net/APILite/HotelSearch/V1/"
key="cyg***********" ←ここのIDは各自で設定のこと
s_area="136202" name="銀座・晴海・築地"
icon="images/flag2_brown.png"
/>
</extrainfo>
</photo>この入力XML( コード 12 )中には,もう1種類の拡張情報として,リクルート社が提供する「じゃらん」のホテル情報サービスの型(jalanHotel)を定義している。これはこの付近にあるホテルに関する情報を獲得するために必要な情報を指定するものである。グーグルマップ上では,茶色の旗のアイコンで示すような指定と,じゃらんのWebサービスを呼び出す際のキー情報,場所情報を指定している。茶色の旗をクリックすると,Webサービスから得た情報を吹き出しに編集して 図 14 のように表示される。
このように1つの写真に関連させて,様々な情報を結び付け,利用者の想いを1つのページにマッシュアップしたアプリケーションとして作成することができる。入力XMLを介して,様々なWebサービスを呼び出しうまく連携させることによって,新たなアプリケーションが実現できることがわかる。1つの情報を基に様々なWebサービスが,直列的に,又は並列的に連携させることから,このようなデータを,ピボットデータと呼んでいる。このピボットデータをうまく設定し,活用することでこれまでにない新たなアプリケーションが出現することが期待できる。
これまではWebサイト上にあるXML,XSLTを指定して出来上がったものを見ているだけであった。今度は利用者が参加して,実際にXMLデータを触ってどの様に表示が変わるのかを実際に試してもらいたい。写真及び旗のアイコンはローカルな環境のものは使えないので,ダウンロードするのは,XMLとXSLTだけである。
ここでは,グーグルマップを利用する例(例3)について実際に見てみる。次の手順で準備をしていただきたい。
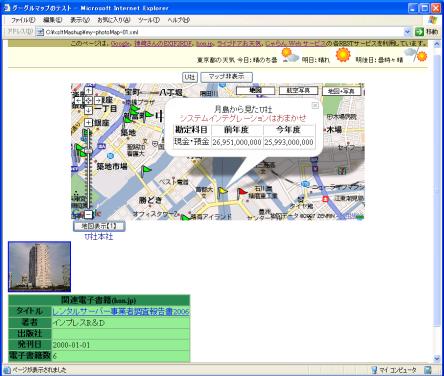
それでは,ダウンロードした入力XML(photoMap-01.xml)に,実際に少し手を加えて見る。変更後のファイル名を"my-photoMap-01.xml"( コード 13 参照)とする。
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="photoMap-01.xsl.xml"?>
<photoMap xmlns="urn:myPhoto" xmlns:html="http://www.w3.org/1999/xhtml">
<initialLoadMap lat="35.659437" long="139.791735" label="U社">
<description flagIconUrl="images/flag2_blue.png"
>U社:江東区豊洲</description>
</initialLoadMap>
<photo href="http://www.xmlconsortium.org/wg/web2.0/mashups/xslt/photos/uBuild.jpg"
label="U社"
>
<title>U社本社</title>
<description flagIconUrl="images/flag2_yellow.png">
<html:div>月島から見たU社</html:div>
<html:div style="color:brown;">システムインテグレーションはおまかせ</html:div>
</description>
<keywords>
<keyword>システムインテグレータ</keyword>
</keywords>
<extrainfo>
<info type="xbrl-bs1"
url="http://・・中略・・/xbrl/bs-NUL061-xbrl.xml"
/>
<info type="jalanHotel"
url="http://jws.jalan.net/APILite/HotelSearch/V1/"
key="cyg***********" ←ここのIDは各自で設定のこと
s_area="136202" name="銀座・晴海・築地"
icon="images/flag2_green.png"
/>
</extrainfo>
</photo>
</photoMap>ここでの変更のポイントは,
また,じゃらんWebサービスを使って,銀座・晴海・築地地区のエリアコードを指定しているので,地図上では緑の旗の位置にあるホテルの情報があることがわかる。実際に幾つかの緑の旗をクリックしてみると,ホテルの写真が現れるはずである。実はこの例では位置情報の持ち方の単位(測地系)が,じゃらんWebサービス(日本測地系)とグーグルマップ(世界測地系)で異なるために,位置が少しずれているのだが,お分かりだろうか。実際に利用するときには,測地系をあわせることに注意が必要である。
入力XML( コード 13 )において,更にkeyword要素を"コンピュータ"に変更するとか,info要素にて,type属性の値を"xbrl1-bs2"に戻すとかして,異なる表示になることを試してみて頂きたい。 GPS付きカメラや携帯電話を持っている人は,写真をWebサイトに公開して,その写真のURLを入力XML内に設定し,若干のコメント,キーワードを加えて,簡単にマッシュアップできることを試行すると良いだろう。更に興味のある人は,XSLTのソースを見て,様々なチャレンジをしていただきたい。
最後に,マッシュアップをする際には,利用するサービスの利用条件を満たすように注意が必要であることを付け加えておく。個人的に利用する場合には問題になることが少ないと思われるが,商用で利用する場合には特によく注意していただきたい。また,サービス提供が突然停止してしまったり,インタフェースが変わることが起こり得ることなどにも気をつける必要がある。上で紹介したWebサービスが使えなくなった場合にはご容赦願いたい。商用で利用する際にはこのような条件も含めて,はっきりとさせておくことが必要であろう。それらを頭に入れながら,まずはマッシュアップを試していただきたい。
本頁の著作権: Copyright (c) XML コンソーシアム 2007 All rights reserved. Copyright (c) 日本ユニシス株式会社 2007 All rights reserved.